




人工智能简要发展史
by

张可
人工智能简要发展史
达特茅斯会议
达特茅斯会议是公认的人工智能成为一个新的研究领域的开端。
1955年夏天,麦卡锡去 IBM 做临时工,当时他的老板是纳撒尼尔·罗切斯特(Nathaniel Rochester,1919—2001),他是IBM公司信息中心的主任,也是第一代通用的商用计算机“IBM 701”的主设计师。
两人都对机器智能感兴趣,于是决定发起一场与机器和智能领域有关的活动,并且给出了如下七个明确的讨论范围:
- 自动计算机:所谓“自动”指的是可编程的计算。
- 编程语言:这里并不同于今天的Java、C、C++等编程语言,而是“如何为计算机编程使其能够使用人类语言”的意思。
- 神经网络。
- 计算规模理论(Theory of Size of a Calculation):这个议题说的是如何衡量计算设备和计算方法的复杂性。
- 自我改进:这个议题就是说机器学习。
- 抽象概念:令计算机可以理解和存储那些人类可以轻易判别,但是难以精确定义的概念。
- 随机性和创造性。
人工智能夏季研讨会”(Summer Research Project on Artificial Intelligence)

达特茅斯会议参会人员的合照,从左到右依次为塞弗里奇、摩尔、所罗门诺夫、明斯基、罗切斯特、麦卡锡、香农。
符号主义学派
符号主义学派的思想和观点直接继承自图灵,提倡直接从功能的角度来理解智能。
利用“符号”(Symbolic)来抽象表示现实世界,利用逻辑推理和搜索来替代人类大脑的思考、认知过程,而不去关注现实中大脑的神经网络结构,也不关注大脑是不是通过逻辑运算来完成思考和认知的。
也就是通过形式化的方式研究智能,从简单到复杂地证明一系列命题来建立整套理论的研究问题的方式称之为“公理化方法”。公理化的思想早在欧几里得撰写《几何原本》时就已经存在。
推理期
对于符号主义学派长达数十年的探索研究过程,根据研究的主要问题不同,可以将其划分为三个阶段:最初这派的学者并未过多考虑知识的来源问题,而是假设知识是先验地存储于黑盒之中的,重点解决的问题是利用现有的知识去做复杂的推理、规划、逻辑运算和判断,这个时期称为符号主义的“推理期”。
认知派
在符号主义学派中,以纽厄尔和司马贺为代表的这一系分支又被称为“认知派”。
逻辑理论家(Logic Theorist)
逻辑理论家是由艾伦·纽厄尔、司马贺和约翰·克里夫·肖于1955年和1956年间编写的计算机程序,是首个可以自动进行推理的程序,被称为“史上首个人工智能程序”。 它最后证明了在怀特黑德和罗素合作撰写的数学原理中首52个定理中的38个,在当中更是找到既新颖又优雅的证明。
一般问题解决器(General Problem Solver, GPS)
1957年,在逻辑理论家公布后不久,纽厄尔和司马贺还发布了一款更具有普适性的问题解决程序,命名为“一般问题解决器”(General Problem Solver, GPS)。
GPS解决问题的基本思路不同于逻辑理论家,它源于模仿人类解决问题的启发式策略,是基于一种在心理学中的“手段-目的分析”(Means-Ends Analysis)的理论。
GPS的工作思路大致是这样的:人通常会把要解决的问题分析成一系列子问题,并寻找解决这些子问题的手段,通过解决这些子问题,就能逐渐达成问题的最终解决,GPS解决问题的方法就是模拟这个问题分解的过程,逐步分解问题空间,通过拆分子问题构建搜索树,直到到达已知条件结束搜索。
其中最有价值的案例是计算机(在人类辅助剪枝、修正下)证明了当时世界三大数学猜想之一的四色猜想,尽管很多数学家认为靠运算速度暴力搜索的方法很不优雅,但这个成果依然震撼了整个数学界。

四色猜想的一个例子
物理符号系统
物理符号系统是纽厄尔和司马贺总结提出的一套尝试解释智能来源机制的理论,它试图模拟人类如何获取、储存、传播和处理信息的,并提供了一种将这个过程中各种现象模型化,迁移到计算机中实现的途径。
符号主义学派的核心观点即“认知的本质是处理符号,推理就是采用启发式知识及启发式搜索对问题求解的过程”。
逻辑派
与“认知派”相对,符号主义学派中另外一位主要人物麦卡锡则认为机器不需要模拟人类的思想,而应尝试直接找出抽象推理和解决问题的本质,只要通过逻辑推理能展现出智能行为即可,大可不必去管人类是否使用同样方式思考。所以,由他开创的斯坦福大学一系主要致力于寻找形式化描述客观世界的方法,通过逻辑推理去解决人工智能的问题,因此这一系在符号主义学派中又被称为“逻辑派”。
常识编程
在麦卡锡看来,对于特定问题的解决方法是“知识”,对于普适智能行为则需要“常识”才行,因此,当人工智能在人机对弈、计算机定理证明等几个特定领域取得了初步成果之后,麦卡锡就开始着手解决“如何才能令机器拥有常识”这个更能说明机器可以拥有智能的问题。
1958年,麦卡锡发表了一篇名为《常识编程》(Programs With Common Sense)的论文,文中提出了一种如何将计算机所处理问题的范围从特定专业领域推广至常识、生活等一般性问题的设想。麦卡锡设计了一个名为“AdviceTaker”的理想系统,这是一款以形式语言(譬如就以使用谓词逻辑为例)为输入和输出项的计算机程序,它基于一系列也是使用形式语言来描述的先验前提,根据逻辑规则自动推理获得问题的答案。答案可能是一个陈述句用以回答一个具体问题,也可能是一个祈使句用以向使用者提供一个行动建议。
麦卡锡期望提供给AdviceTaker的先验的知识是我们人类所了解的各种知识、常识中最基础、最本质的那一小部分,AdviceTaker先使用这些先验的前提推理出简单的结论,然后再到复杂的,形成越来越多的新的知识,并能根据这些知识持续改进自己的行为机制,从简单到复杂逐步获得人类所有乃至超过人类现有的知识。麦卡锡将这样一套理想的系统和运作机制称为“常识编程”。
可是,AdviceTaker其实并未解决“常识来源自哪里?”这个真正的难题,在上面这个例子中,诸如go、walkable、drivable、canachult、want这些谓词的定义,都是人类总结后灌输进去的,而不是计算机从某种“公理”或者“公设”性质的常识中推导而来。
他在1960年又发表了一篇名为《递归函数的符号表达式以及由机器运算的方式,第一部分》(Recursive Functions of Symbolic Expressions and Their Computation by Machine, Part I)的论文。论文阐述了只通过七个简单的运算符以及用于函数的记号来构建一个具图灵完备性语言的想法,并将这种语言命名为LISP。

知识期
后来大家发现智能的体现并不能仅依靠推理来解决,先验的知识是更重要的一环,研究重点就转变为如何获取知识、表示知识和利用知识,这个时期称为符号主义的“知识期”。
另外,由于考古学对古代智人的研究得出了古代智人与现代人类在脑容量上并没有差距的结论,这个结果表明了人类智能行为表现出的问题求解能力更多是来源于人所具有的知识,而不仅仅是大脑思考和推理的能力。
从此,人工智能的主要研究方向便从“逻辑推理”转到了“知识的表述”上,符号主义学派从“推理期”转入“知识期”的标志是三类“知识”研究开始被科学界关注而且取得了一定进展,它们分别是:“知识表示”出现了被广泛认可的方法、“知识工程”被提出和作为独立的学科进行研究以及以专家系统为代表的“知识处理系统”开始展现出实际应用的价值。
学习期
在知识系统的研发和建设的过程中,人们就已经认识到了获取知识将会是这种系统的最大瓶颈所在,依赖人类专家给机器灌输知识,仅限于某个专业领域中还有些许可行性,但对于多数领域而言,靠人类专家是无论如何都不可能跟上知识膨胀的速度的。
因此,随着知识系统研究的深入,人工智能学界重点关注的问题,又回到了“如何让机器有自我学习改进的能力”上,这个时期便是符号主义的“学习期”。
70年代后期,机器学习重新成为符号主义学派主流研究方向的时候,其学习过程就不能再是简单的“死记硬背”了,这个时期的机器学习追求的目标是从大量样本数据中自动总结提炼出隐藏在数据背后的知识,得到这些知识的形式化描述。或者简单地说,这种机器学习的目的是寻找隐藏在样本数据背后的规律(Rule)。因此,这个阶段的机器学习被称为“基于符号的机器学习”或者“基于规则的机器学习”。
基于符号的机器学习是从样本中总结得出知识,而前文曾提到推理期时科学家希望从少量最基础最本质的知识推导其他知识,这两个思路正好就对应了人类认知世界的两种手段:演绎和归纳。在逻辑学中相对更重视演绎,但在人类的现实生活中,归纳却是人类认知世界更常用的工具。
决策树
基于符号的机器学习算法中最成功、应用最为广泛的就非“决策树学习”莫属了。
女儿:多大年纪了? 母亲:26。 女儿:长的帅不帅? 母亲:挺帅的。 女儿:收入高不? 母亲:不算很高,中等情况。 女儿:是公务员不? 母亲:是,在税务局上班呢。 女儿:那好,我去见见。
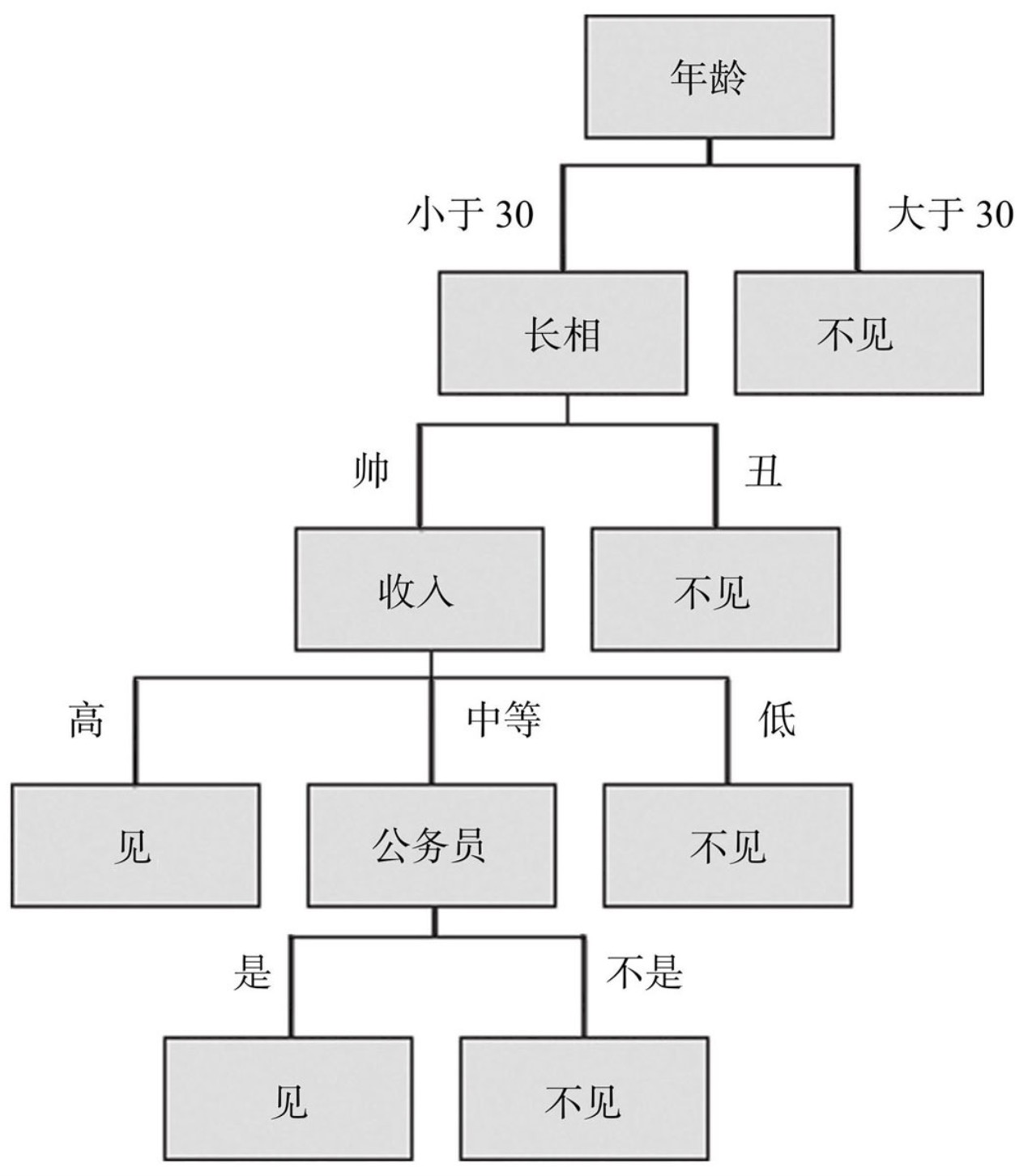
决策树学习算法的核心是从训练集中自动归纳出一组分类规则,使得这组规则不仅能适应已知的训练样本,对于与样本同分布的未知新数据也有一致的泛化性能。
对比现在最热门的基于神经网络的机器学习,以决策树学习为代表的基于符号的机器学习有一个很好的性质:它生成的模型是一个白盒模型,输出结果的含义很容易通过模型的结构来解释,而神经网络输出的是一个黑盒模型,最终结果往往是模型确实可以解决问题,甚至是工作得非常好,但是人类无法根据模型去解释为什么会如此。可解释性是符号主义思想先天决定的,这也是基于规则学习算法对比起现在流行的基于神经网络学习算法的一个巨大优势。
符号主义的没落
80年代,随着符号主义最后一个阶段“学习期”进入尾声,它也逐渐丧失了在人工智能这门学科中的主导地位,符号主义面临的主要困难有两点。
一是“智能”实在太过复杂、抽象,很多问题往往无法被形式化,也不清楚背后的运作机制,以至于在其他科学里一直行之有效的“根据具体现象,总结一般规律”, “根据客观规律,推理未知现象”的研究方法在研究智能时,竟都显得有点无从下手。
二是符号主义中的主要理论实现起来始终受到“NP完全问题”的困扰,即使很多理论上可行,至少值得去试一试的研究方法,都因为最后被证明是“NP完全问题”,无法逃脱指数级别时间的增长,无法不打折扣地应用于智能的探索实践。
连接主义学派
连接主义学派主张通过模拟大脑的物理结构来获取智能。它认为智能是由神经元之间的连接和相互作用产生的。连接主义学派的理论基础是人工神经网络,它的研究重点是如何从数据中学习知识和模式,并且能够对未知数据进行推理和分类。
1904年,西班牙病理学家拉蒙·卡哈尔(Ramon Cajal,1852—1934)提出了人类大脑包含大量彼此独立而又互相联系的神经细胞的神经元学说。
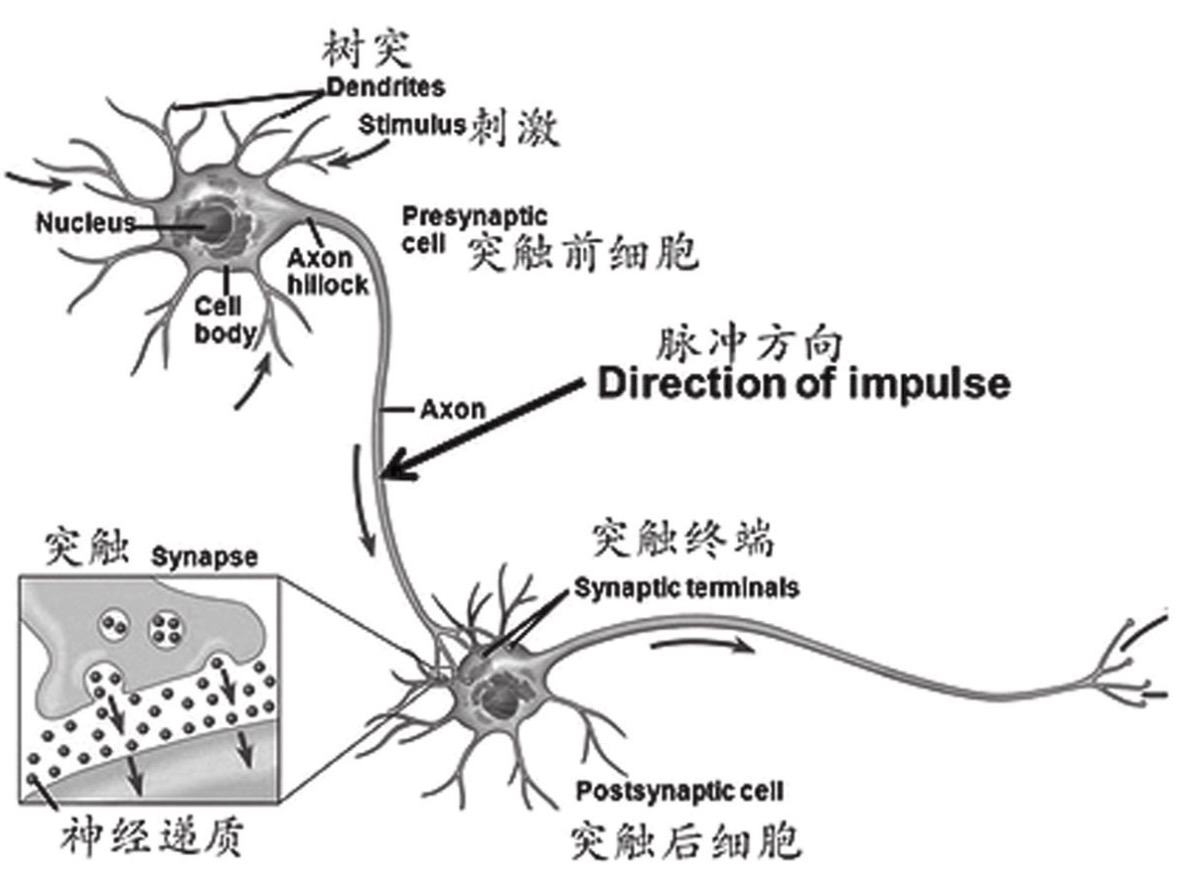
M-P神经元模型
1943年,心理学家沃伦·麦卡洛克(Warren McCulloch,1898—1969)和皮茨在《数学生物物理学通报》上发表论文《神经活动中内在思想的逻辑演算》(A Logical Calculus of The Ideas Immanent in Nervous Activity),文中讨论了理想化、极简化的人工神经元网络,以及它们如何形成简单的逻辑功能,首次提到了人工神经元网络的概念及数学模型,从而开创了通过人工神经网络模拟人类大脑研究的时代。后来人们将这种最基础的神经元模型命名为“M-P神经元模型”。

麦卡洛克和皮茨的《神经活动中内在思想的逻辑演算》一文被认为是连接主义研究的开端,提出了机械式的思维模型,该文章的重要贡献还在于首次提出了“神经网络”(Neural Network)这个概念。将这个模型称为“M-P神经元模型”。
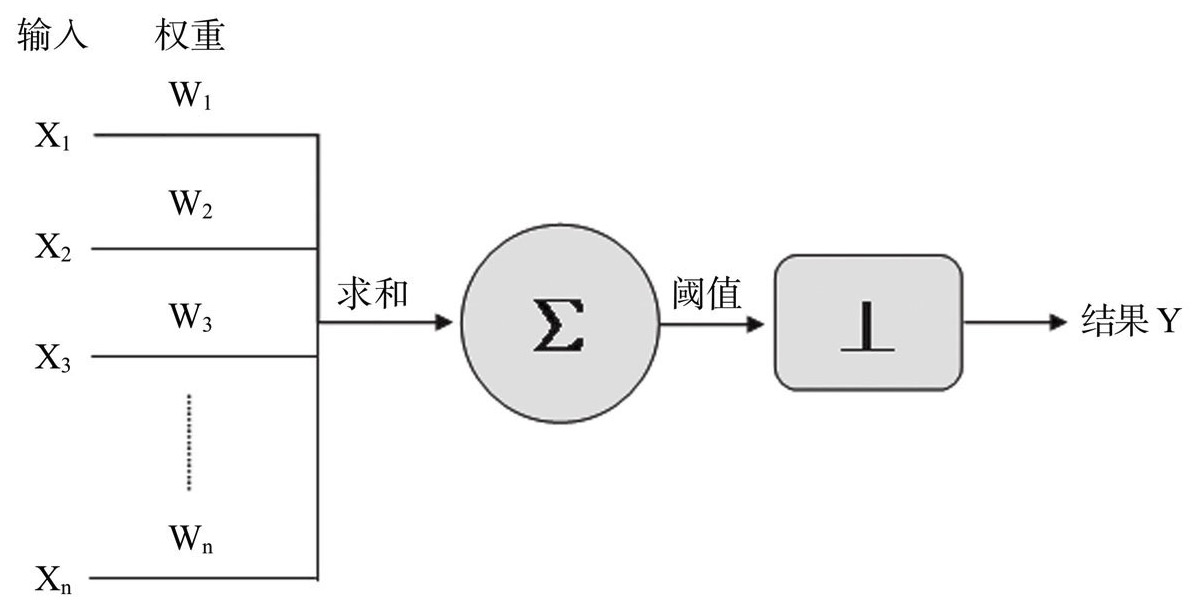
感知机
1949年,心理学家唐纳德·赫布(Donald Hebb,1904—1985)在《行为组织学》(The Organization of Behavior)这部著作中提出了基于神经元构建学习模型的法则。他认为神经网络的学习过程最终是发生在神经元之间的突触部位,突触的联结强度随着突触前后神经元的活动而变化,变化的量与两个神经元的活性之和成正比。该方法称为“Hebb学习规则”(Hebb’s Law)。

罗森布拉特和他发明的第一台感知机 Mark-1
罗森布拉特(Frank Rosenblatt)是一位美国心理学家、信息科学家,也是神经网络领域的先驱之一。他于1957年提出了感知机(Perceptron)模型,这是一种最早的神经网络模型。感知机模型可以用来解决二分类问题,被广泛应用于模式识别、计算机视觉等领域。
神经网络在工程应用上真正有实用意义的重大突破发生于1957年。康奈尔大学的实验心理学家罗森布拉特在一台IBM 704计算机上模拟实现了一种他发明的叫作“感知机”(Perceptron)的神经网络模型,这个模型看似只是简单地把一组M-P神经元平铺排列在一起,但是它再配合赫布法则,就可以做到不依靠人工编程,仅靠机器学习来完成一部分机器视觉和模式识别方面的任务,这就展现了一条独立于图灵机之外的,全新的实现机器模拟智能的道路。
数字识别神经网络
待识别的数字通过光学扫描后存储在 14x14 像素大小的二维数组中,其中包含不同类型的数字,如下图:

存储图片的二位数组元素类型为浮点型,表示该像素点的灰度值,用 0-1 区间表示。
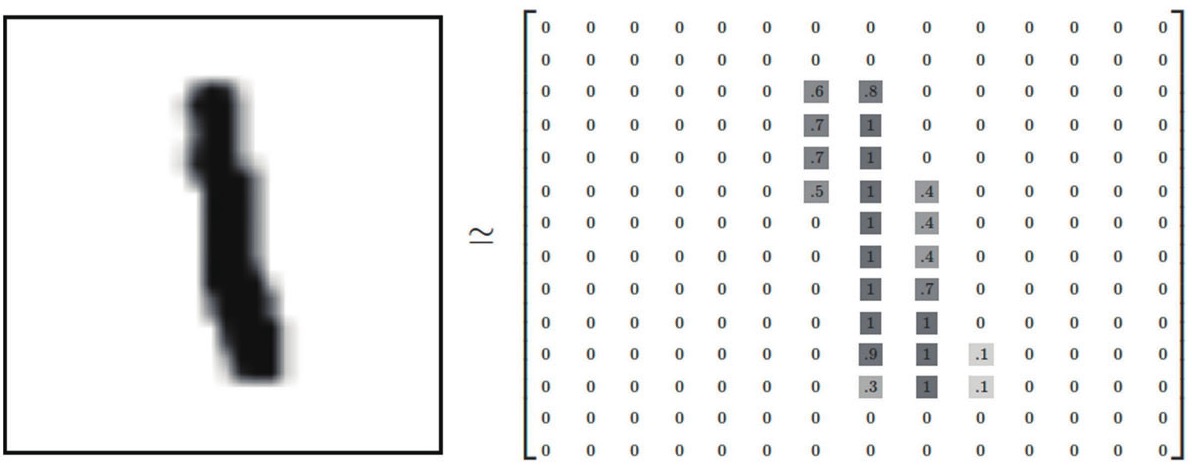
接下来,我们把图片到从“0”至“9”十个数字的分类过程,转化为十个M-P神经元的工作过程。每个M-P神经元有196个(14×14)像素值的输入项,经过训练之后得到的各个像素值在该数字下的权重数据就作为该神经元的196个输入项的加权值,由此构成了一个由10个神经元、共计1960个带权重的连接线组成的神经网络。
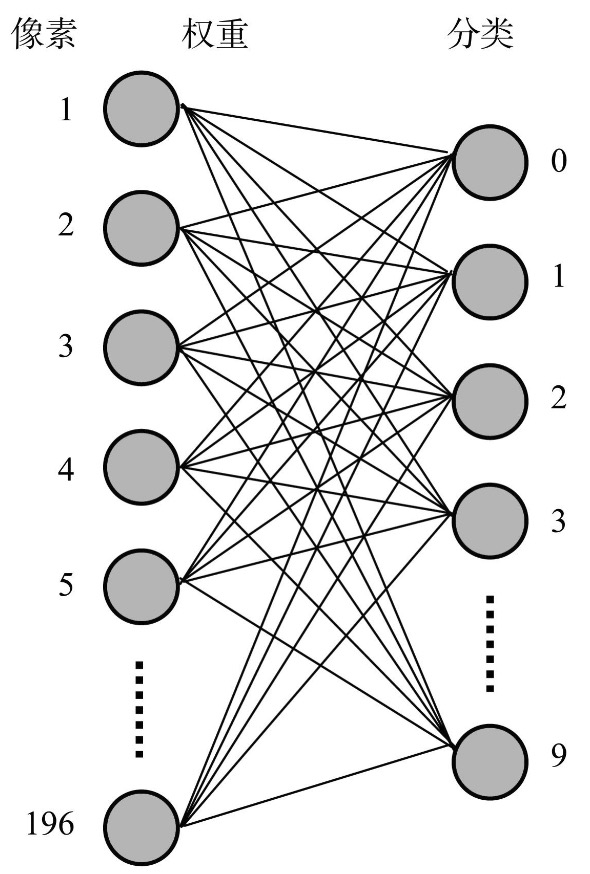
以上就是数字识别神经网络的基本原理。
连接主义的寒冬
罗森布拉特在发明了感知机后声名大噪,一时间政府和各大公司纷纷开始研究人工智能,甚至美国国防部和海军都自助了罗森布拉特的研究工作,而罗森布拉特本人非但不懂得明哲保身,还开始频繁在媒体面前出镜,开跑车,这也导致不少人工智能领域的学者对他都比较反感。
这其中就包括连接主义学派的巨头明斯基。
明斯基是达特茅斯会议的组织者,是人工智能的几位奠基人之一。1959年,明斯基加入麻省理工学院,创立了麻省理工的计算机系以后,其主要工作之一就是与政府机构对接,负责申请研究经费方面的事务,他与罗森布拉特的结怨,最初也是源于这些与学术无关的行政工作。
明斯基为了证明罗森布拉特发明的感知机和神经网络的价值有限,与另一位麻省理工学院的教授摩尔·派普特(Seymour Papert,1928—2016)合作,着手从数学和逻辑上去证明罗森布拉特的理论和感知机具有重大的局限性,没有什么发展前途。他们合作的成果就是那本在人工智能历史上影响巨大的、“是也非也”的传奇书籍:《感知机:计算几何学导论》(Perceptrons: An Introduction to Computational Geometry)。
在《感知机:计算几何学导论》一书里他们同时也指出了感知机的致命弱点:“感知机能解决线性可分的问题,但是它也仅仅能解决线性可分的问题。”两位教授同样用数学方法,证明了感知机,更准确地说是单层的感知机并不能处理非线性数据的分类问题,其中最典型的就是“异或问题”。
明斯基不仅证明了单层感知机的不足,还证明了多层感知机在实际情况下也是不可行的,因为每增加一个隐层产生的连接数量都会急剧增加,并且加入隐层后罗森布拉特的训练方法就会失效,当时的硬件和算法都没有解决这些难题的办法。
1971年7月11日,《感知机:计算几何学导论》公开出版刚满一年,罗森布拉特在43岁生日当天,在美国切萨皮克湾的一艘游船上“意外”落水,不幸身亡。
深度学习时代
连接主义以及神经网络在经历上次的低谷之后从一个极端走到了另一个极端,学术界甚至将神经网络视为异端,政府和机构几乎都暂停了对相关研究的资助,只剩下一小批学者还在坚持研究,其中最重要的人物就是被称为深度学习之父的多伦多大学计算机科学系的杰弗里·辛顿(Geoffrey Hinton, 1947—)教授。

1947年末,辛顿出生在战后的英国伦敦小镇温布尔登(Wimbledon),成长于布里斯托尔(Bristol)。辛顿诞生于一个富有传奇色彩的学者家族,这个家族在各个领域出过很多著名学者,前面章节中出现过几次的那位创立布尔代数的逻辑学家乔治·布尔(George Boole,1815—1864)便是辛顿的曾曾祖父,而他的曾祖父查理斯·辛顿(Charles Hinton,1853—1907)是一位数学家,更是著名的科普和科幻小说作家,写有《第四维空间》(The Fourth Dimension)等作品。辛顿的父亲霍华德·辛顿(Howard Hinton,1912—1977)是一名昆虫学家,他的两位堂兄妹在中国很是有名,堂弟叫William Hinton,还有一个堂妹叫Joan Hinton,他们两位有自己的中文名字,一个叫韩丁,一个叫寒春,都是进过课本的中国人民老朋友,著名的马克思主义者,参加过曼哈顿计划为美国制造原子弹,但心怀解放全人类的理想来到了共产主义中国,并成了第一位获得“中国绿卡”的国际友人。
辛顿在60年代他念高中时,无意间听到了大脑运作机制以及神经网络的概念,为此深深地着迷,他形容到这是他一生的关键时刻,也是他一生成功的起点。
辛顿高中毕业进入剑桥的国王学院攻读物理和化学,却仅读了一个月后就退学了,一年之后,他再次申请攻读建筑学,结果在建筑系仅仅上了一天课,又决定转学读物理学和生理学,后来发现物理学还是不适合自己,又再次退学。此后,他再改读哲学,但因为与他的导师发生争吵而告吹。最后,他选择研读心理学,直到1970年,终于以剑桥大学国王学院实验心理学“荣誉学士”的身份毕业。
大学毕业后,辛顿搬到了北伦敦的伊斯灵顿区居住,为了生计,他成为一个包工木匠,过着混乱不堪,近乎潦倒的日子。
在离开大学校园最好最安静的学习环境之后,辛顿反而能够平静地追求他所向往的机器模拟人类大脑来。每个星期六早上,他都会去伊斯灵顿的埃塞克斯路图书馆,靠着图书馆里的资料自学了解大脑的工作原理,这样的平淡日子过了两年后,辛顿反而又通过发表论文和参加学术会议,重新折腾回学术圈,大概这就是辛顿“逆反”的教育心态的第一次体现。从1972年开始,辛顿从一个木匠,重新变回一位学者,进入爱丁堡大学攻读博士学位,而且还是师从大化学家克里斯多福·希金斯(Christopher Higgins,1923—2004)教授,他选择的研究方向自然就是神经网络。
复兴之路
对于单层神经网络而言,因为它只有一个输入层和一个输出层构成,输出层输出值与实际值之间的误差是显而易见的,我们要得到模型的权值参数,直接对损失函数求导然后应用梯度下降算法优化即可。
可是应用在多层神经网络情况就复杂多了,由于有了中间隐层的存在,它作为下一层神经元的输入,是通过一层层传到输出层之后,才能间接影响模型的输出结果的,每一个隐层神经元的输出都不是神经网络的最终输出值,不能直接拿来和实际值比较误差,这样就没有办法直接通过对损失函数求导得到梯度来计算出各个隐层的各个神经元的权值参数了。
出了这些原因之外,神经网络的低谷还有个原因就是当时冰冷的学术氛围,实际上当时已经有了能很好解决这些问题的算法了,也就是后来被辛顿命名为 误差反向传播算法 的训练方法。
但最终要到1986年,辛顿与心理学家大卫·鲁梅尔哈特(David Rumelhart,1942—2011)在《自然》杂志上发表了论文《通过误差反向传播算法的学习表示》(Learning Representations by Back-propagating Errors)才真正引起了学术界的关注。
在《自然》这种顶级科学杂志上,辛顿清晰论证了“误差反向传播”(Back-Propagating Errors)算法是切实可操作的训练多层神经网络的方法,才得以彻底扭转明斯基《感知机》一书带来的负面影响,终于令学术界普遍认可多层神经网络也是可以有效训练的,神经网络并不是没有前途的“炼金术”。直到此时,神经网络的“生存危机”才算是初步化解,误差反向传播算法对神经网络来说可谓是期盼已久,能称作雪中送炭的重要成果,神经网络也由此踏出了它的漫长复兴之路的第一步。
从感知机到神经网络
多层感知机一般以“全连接前馈神经网络”(Fully Connect Feedforward NeuralNetwork),这种形式出现。
其名字中的“前馈”(Feedforward)是指把若干个单层神经网络联在一起,前一层的输出作为后一层的输入,就构成了最基础的一种多层神经网络。神经网络加上“前馈”这个定语,目的在于特别强调这样的网络是单向的、无反馈的,就是说位置靠后的神经元不会把输出反向连接到前面层次上的神经元作为输入。而“全连接”(Fully Connect)就很好理解了,是指网络中任意一个神经元与其上、下层的每一个神经元都有连接相连,“全连接”带来的主要好处是对网络的输入顺序并没有要求,打乱顺序输入也不会对输出结果产生影响。
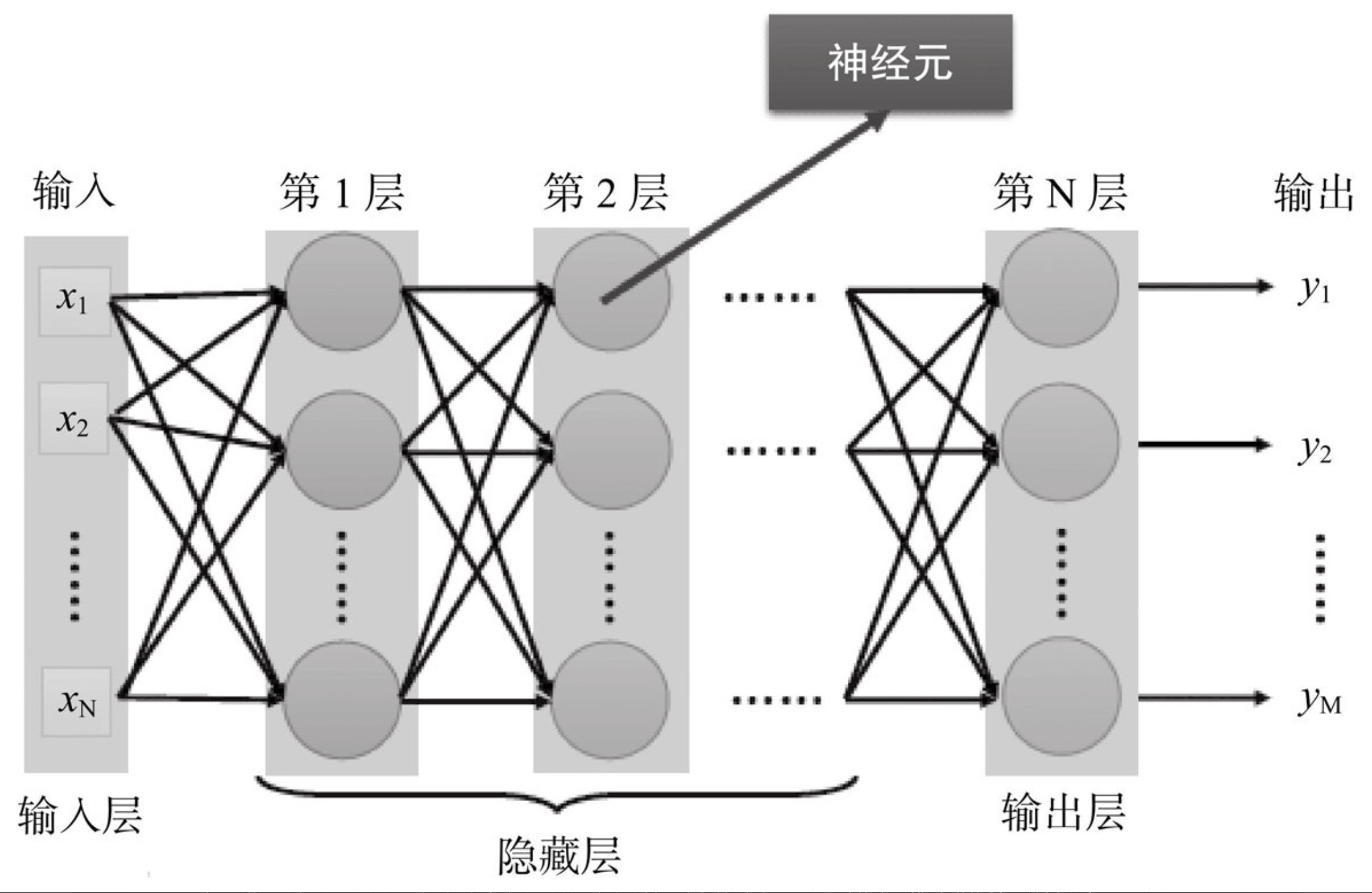
全连接前馈神经网络结构
误差反向传播算法适用的神经网络范围要更大,它不仅可以用来训练多层感知机,也可以用来训练不是全连接的、不是前向的神经网络,例如循环神经网络就是具备反馈连接的,同样可以使用误差反向传播算法。
除此之外,现在大多数神经网络还具备一个特质就是他们所采用的激活函数都不相同。
多层感知机的激活函数一般知识简单的对比输入与阈值,大于等于阈值就会输出,否则就忽略输入信号。
“激活函数”(Activation Function,也常被译为“激励函数”)的作用就是为了给神经网络加入非线性的表达能力,它改进了阈值函数只能单纯比较大小判断是否激发神经元信号的简单逻辑,允许根据实际需要,对输入的加权和进行不受限制的数学处理。
误差反向传播算法的提出,成功解决了多层神经网络训练可行性的问题,不过,这也仅仅是神经网络复兴的第一步,距离全面复兴,走到今天深度学习的时代,还有一段漫长曲折的旅途。
深度学习
由于找不到合适的经费来源,辛顿辗转在瑟赛克斯大学、加利福尼亚大学圣地亚哥分校、卡内基梅隆大学、英国伦敦大学等多所大学工作过,最后终于在2004年从加拿大高等研究院(Canadian Institute For Advanced Research, CIFAR)申请到了每年50万美元的经费支持,加拿大高等研究院可能是那个时候唯一还在支持神经网络研究的机构了,现在看来这是一笔收益比例惊人的投资。
辛顿当时申请了研究课题为“神经计算和适应感知”的项目,虽然与其他知名的人工智能项目所得到的巨额资金相比,每年50万美元实在是一笔微薄的经费,但还是让辛顿在加拿大多伦多大学安顿下来,结束了飘摇不定的访问学者生涯。
一直到2006年之前,经过三十多年的耕耘,辛顿在人工神经网络领域已经算是一位泰斗级人物,硕果累累,荣誉等身,1998年就被选为英国皇家学会院士。但辛顿在学术上的成就,还是抵不过大众脑海里“神经网络是没有前途”的偏见,在很长一段时间里,多伦多大学计算机系私下流行着一句对新生的警告:“不要去辛顿的实验室,那是没有前途的地方。”即使如此,辛顿依然不为所动,仍坚持自己的神经网络研究方向没有丝毫动摇。
猫咪的视觉实验
在1959年的一次实验中,休伯尔和威泽尔将玻璃包被的钨丝微电极插入麻醉猫的初级视皮层,然后在置于猫前方的幕布上投射出一条光带,改变光带的空间方位角度,用微电极记录神经元的发放。
他们发现当光带处于某个空间方位角度时,发放最为强烈。而且不同的神经元对不同空间方位的偏好不尽相同。还有些神经元对亮光带和暗光带的反应模式也不相同。休伯尔和威泽尔将这种神经元称为简单细胞。
初级视皮层里另外的那些神经元,叫做复杂细胞,这些细胞对于其感受野中的边界信息比较敏感,还可以检测其感受野中的运动信息。这些研究给人们展示了视觉系统是怎样将简单的视觉特征在视皮层呈现出来的。
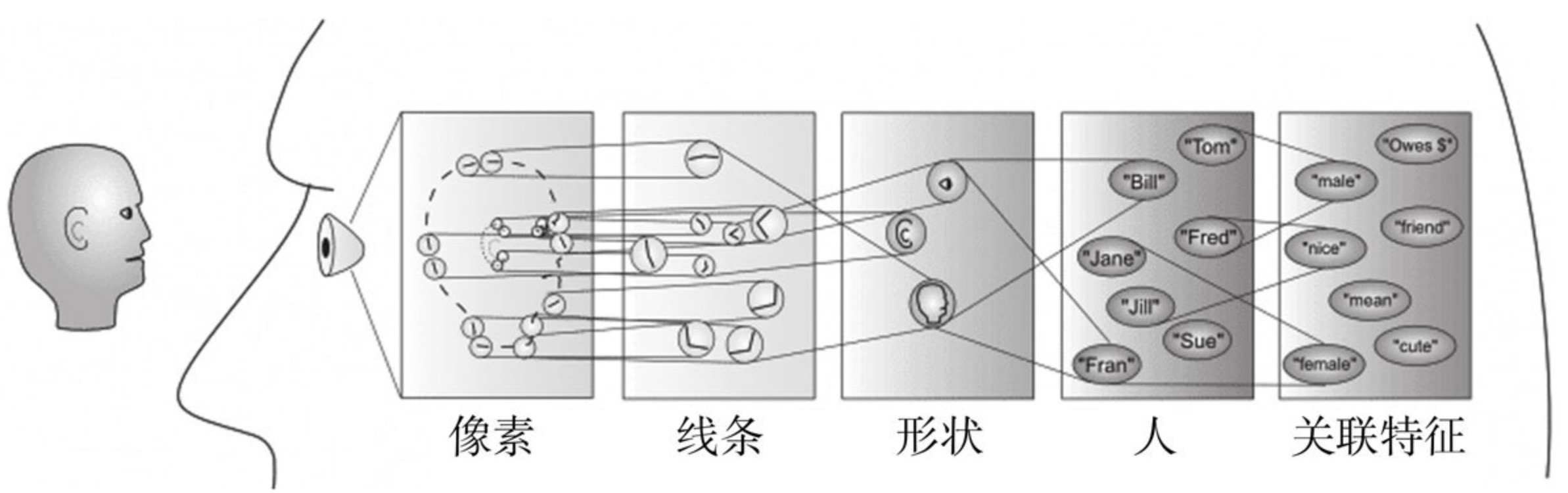
信息从“视觉细胞”到“中枢神经”再到“大脑”的流动过程,或许是一个分层迭代、逐级抽象的过程。这里的关键词有两个,一个是“抽象”,一个是“迭代”,从原始信号输入开始,先做低级的抽象,逐渐向高级抽象迭代。
在50年代的这个神经生理学的发现,促成了计算机人工智能在半个世纪后(2006年)的突破性进展。现代科学已经基本确定了人的视觉系统的信息处理的确是分级的,从最低级像素提取边缘特征,再到稍高层次的形状或者目标的部分等,再到更高层的整体目标,以及目标的行为和其他特征的联想等。换句话说,高层的特征是低层特征的组合提炼,从低层到高层的特征表示越来越抽象,越来越能表现出认知的意图。抽象层面越高,存在的可能猜测就越少,就越利于分类。
人类认知过程与深度学习之间可能出现的共通点了,即“分层迭代、逐级抽象”。
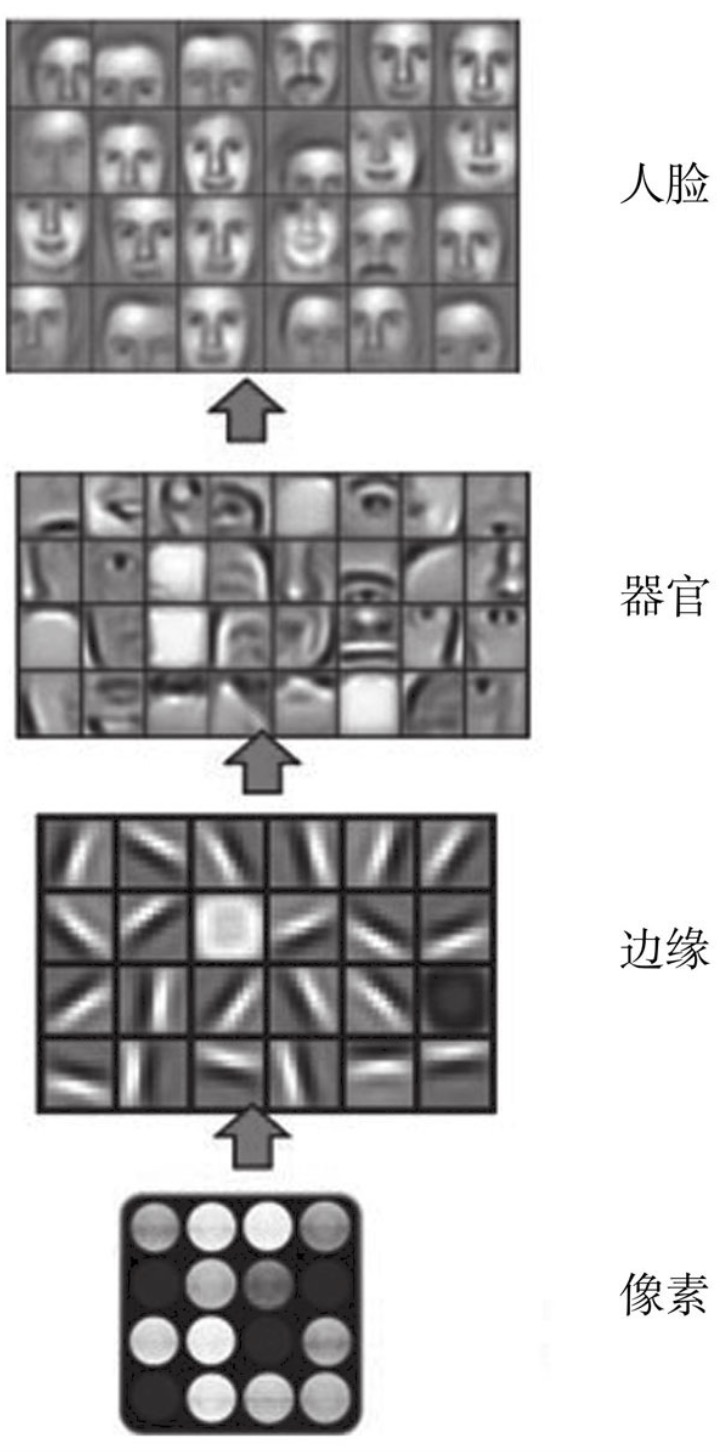
机器的认知过程
深度学习的本质,就是一种逐层自动进行特征提取的机器学习方法,如上图所示,这是深度学习下计算机如何从图片中识别人的典型过程。
深度学习还有另外一个更为贴切的名字,叫作“无监督特征学习”(Unsupervised Feature Learning),这就更加可以顾名思义了:“无监督”的意思即不需要人工参与特征的选取过程,这点才是深度学习的最大特点。
深度学习元年
2006年被认为深度学习时代的元年,深度学习时代的序幕的开启,是以辛顿这一年发表的两篇论文为标志的。第一篇是辛顿和他的学生拉斯·萨拉克赫迪诺弗(Ruslan Salakhutdinov)在美国著名的《科学》杂志上发表的,名为《通过神经网络进行数据降维处理》(Reducing the Dimensionality of Data with Neural Networks)的论文。这里“数据降维”的方法就是用神经网络自动进行特征选择和提取,此文实质性地开创了“深度学习”这个机器学习的新分支。
辛顿在同一年发表的另外一篇文章《一种基于深度信念网络的快速学习算法》(A Fast Learning Algorithm for Deep Belief Nets)再次对“深度”这个词进行定义和包装,才变得火爆起来的。
深度学习能够自动找出关键特征的特性,是对应用神经网络解决机器学习问题的极大解放,这点是深度学习的革命性突破。
常见的神经网络类型
卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)可以说是深度神经网络中最有影响力的一种模型,今天它早已是大名鼎鼎,从某种意义上它还是为深度学习打下大好江山的第一功臣。卷积神经网络同时也是一个很好的计算机科学从脑神经科学借鉴并获得成功的例子,它的思路与人脑和视觉系统分层抽象识别物体的过程极为相似。
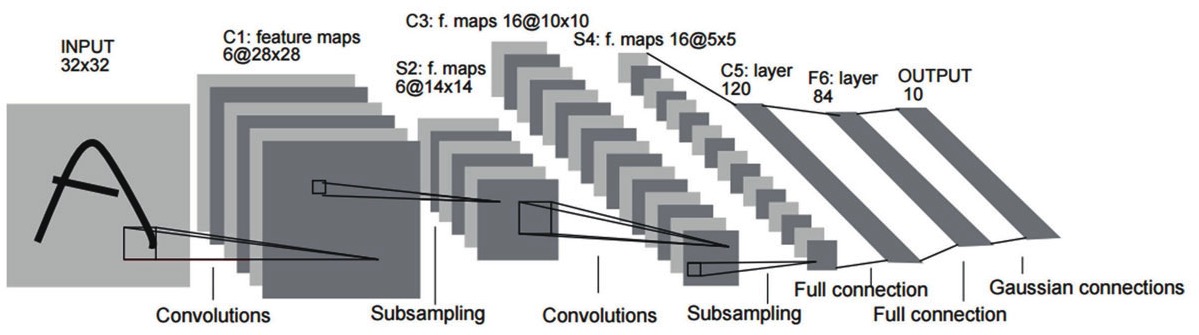
LeNet-5网络
“卷积”(Convolution)原本是数学的泛函分析中的概念,它是一种数学计算,信号变换中经常要使用到它。而在我们现在讨论的语境里,它是一种特征提取操作,卷积最初被引入神经网络,就是为了处理模式识别中图像特征提取的,它就像是一个漏斗,不断在图片中平移,从下层图像中筛选数据,这个“漏斗”(专业上称作“卷积核”, Convolution Kernel)可以是各种形状的。经过漏斗过滤后,筛掉了一些数据,但可以获得更高维度的特征。譬如漏斗从像素中找出边缘,从边缘中找出形状,从形状中找出物体,漏斗对数据运算处理,就像是人脑对物体分层抽象的过程。
卷积神经网络可以处理大部分格状结构化数据。举个例子,图片的像素是二维的格状数据,声音序列在等时间上抽取相当于一维的格状数据,而视频数据可以理解为对应视频帧宽度、高度、时间的三维数据。
循环神经网络
循环神经网络(Recurrent Neural Network, RNN)是深度神经网络的另一种常见应用形式。
自然语言处理是循环神经网络最适合的舞台,发展到今天,循环神经网络已经成为了这个领域的主要工具之一。
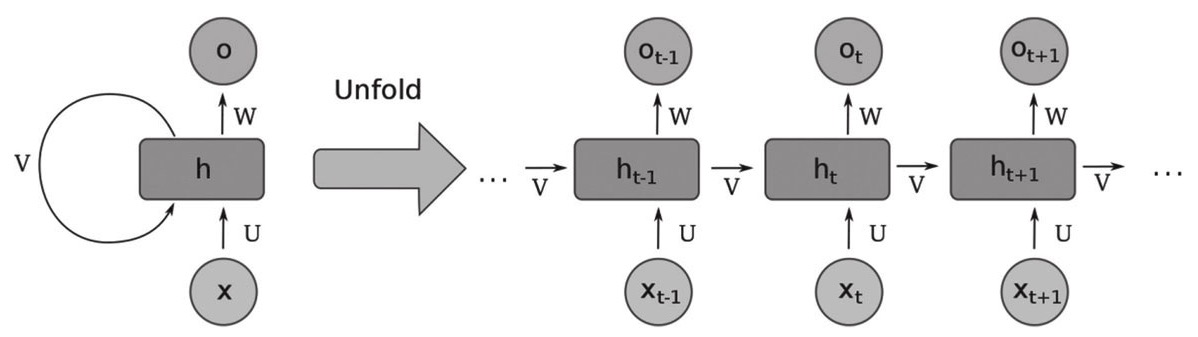
循环神经网络按时间序列展开的结构图
循环神经网络已经广泛应用于语音分析、文字分析、时间序列分析。如果主要解决的问题就是数据之间存在前后依赖关系、有序列关系,现在一般首选长短期记忆网络,如果预测对象同时取决于过去和未来,可以选择双向结构,如双向长短期记忆网络。
对抗式生成网络
“生成式对抗网络”(Generative Adversarial Networks, GAN)与卷积神经网络和循环神经网络不同,一般不用于做分类和预测等工作,从名字上就可以看出,它施展的舞台主要在“生成”(Generative)这个词上。
2014年,奥本希的得意门生、OpenAI和谷歌大脑的青年科学家伊恩·古德费洛(Ian Goodfellow,1985—)发表了一篇论文《生成式对抗网络》(Generative Adversarial Networks)是这个领域的开山之作。
谷歌2017年提出了一项叫作“像素递归超分辨率”(Pixel Recursive Super Resolution)的技术,可以把网格的像素马赛克转换成为肉眼可辨识的人物图像。

一边是生成网络,用于生成图片,这个网络最开始是完全随机的,产出的结果自然也是毫无规律,生成网络一般是用“反卷积神经网络”(Deconvolutional Networks, DN)来实现。另外一边是判别网络,用于判断生成网络中产生的图片是真的符合要求的数据还是伪装的数据。
Transformer 模型
Transformer模型(直译为“变换器”)是一种采用自注意力机制的深度学习模型,这一机制可以按输入数据各部分重要性的不同而分配不同的权重。该模型主要用于自然语言处理(NLP)与计算机视觉(CV)领域。
Transformer模型于2017年由谷歌大脑的一个团队推出,现已逐步取代长短期记忆(LSTM)等RNN模型成为了NLP问题的首选模型。并行化优势允许其在更大的数据集上进行训练。这也促成了BERT、GPT等预训练模型的发展。这些系统使用了维基百科、Common Crawl等大型语料库进行训练,并可以针对特定任务进行微调。
chatGPT 就是基于这个模型进行开发的。
2012 年
深度学习在 2012 年爆发式崛起,除了辛顿提出的可行性方法和理论之外,还有大数据的兴起以及 GPU 为代表的面向大规模并行计算硬件的发展。
辛顿之所以被称为深度学习教父,不仅仅是对深度学习的贡献,也是因为他为这个领域培养了许多优秀的人才,并鼓励他们去 IBM、微软和谷歌等大公司工作。
辛顿成为了一个纽带,促进圈子中不同群体之间的技术和信息流动,并且开放自己实验室的成果,实质性的推动技术落地到产业中去。
2012年,吴恩达与迪恩一起组建起了谷歌大脑计划。项目最开始使用无监督学习来认知世界,谷歌大脑服务器创建了一个有数十亿连接的神经网络,观看了数千万的YouTube影片,在没有任何人的标注下自动识别出了猫,并且自主搜索了猫科动物明星的视频,同年六月份被纽约时报报道。
2012年辛顿带着两名学生创建了 DNNResearch 深度学习公司,2013 年谷歌以5000万美元收购该公司。
2013年谷歌收购 DeepMind 公司。
2013年,燕乐存以纽约大学教授的身份兼职加入Facebook,随后便着手组建了Facebook的人工智能实验室(Facebook AI Research, FAIR)。
2014年,在经历微软全球副总裁长达数月的游说,深度学习三巨头中的最后一位奥本希终于答应加入微软研究院(Microsoft Research, MSR),担任微软研究院的人工智能战略顾问。
深度学习的不足
效率
效率目前深度神经网络的效率其实非常低下,很无奈地说,之所以神经网络和深度学习大行其道,可能是目前我们并没有更好的解决手段。
深度学习就是一种数据驱动的算法,大量的数据是建立精确模型的前提和保证。
深度学习虽然是模拟人脑而来的,但是还远未找到人脑生物结构中的精髓,还处于非常初级的阶段。
理论基础
计算机向人脑学习智能,要有跨越式的突破,关键点大概也不会在于模仿得多么接近人脑结构,而是最终能够发现其中的理论基础,目前神经网络效率不高,就是没有理论基础去指导优化的一种外在表象。
这种仿生的机器学习,现在的基础还不是依赖现实世界的本质规律,其实是依赖大量数据样本中体现出来的规律和特征。
不可解释性
神经网络的不可解释性阻碍了这一技术的抽象和总结,限制了高水平认知智能的研究和发展。
目前的学术界提出的其中一种思路,是希望神经网络这一连接主义的代表性技术能够与符号主义相结合,因为可解释性正是符号主义的强项之一。
灵活性和适应性
目前的神经网络具有高度分化的专一性,只能在特定的问题上具有良好的表现。如果需要解决其他问题,就必须从头开始训练一个全新的神经网络。